Human in the Loop: Guiding AI to Break the Bus–Network Architecture Barrier
A story of AI building PCIe over networking from first principles.
With more than fifteen years in high-performance computing, I’ve worked across chip architecture, PCIe fabrics, GPU clustering, RDMA, CUDA, and cloud infrastructure. For most of that time, the mission was consistent: build better infrastructure so AI systems can scale.
In the AI era, the pressure is the same: make large-scale inference and training faster, scalable, and less painful.
The old instinct is easy to follow—push the bus into a bigger network, scale to larger clusters, add layers of orchestration, and hope the software stack keeps up.
But a harder question emerged:
What if infrastructure can scale below the software stack boundaries?
What if 1000+ GPUs were in one logical host attachment domain, so many programs could scale by seeing more devices without rewriting distributed logic?
Why PCI over network is so hard
“PCI over networking” sounds like a protocol experiment. It is not.
It is a boundary violation.
The Linux PCI subsystem is foundational:
- device discovery
- BAR/window mapping
- DMA behavior
- interrupt routing
- reset and lifecycle semantics
Moving these semantics over the network means preserving deep kernel contracts across transport, not just passing packets.
In Linux, mistakes here don’t fail softly. They fail as unstable or confusing hardware behavior.
What changed with AI in the loop
LLMs are excellent pattern synthesizers.
They can combine examples of drivers, networking, filesystems, compilers, and infrastructure APIs quickly.
But this problem had no public template for “PCI subsystem over TCP in pure software.”
So the core approach became:
- define invariants
- enforce strict process gates
- iterate with evidence from logs, tests, and failure modes
I called this the Human–AI dual loop.
Stage I: velocity vs correctness
I started with a fast loop intended to get to “it runs” quickly.
I used a short loop: read logs, patch code, rebuild, rerun.
What worked:
- quick scaffolding
- visible progress
What failed:
- short-circuited assumptions in BAR handling
- tempting shortcuts like “simulate NVMe behavior on host”
- demos that looked good but drifted from the target contract
The key lesson:
- AI accelerates, but without constraints it can optimize for apparent progress over true architectural completion.
I stopped the shortcut drift and reset the process.
Stage II: Human–Ralph dual loop and deterministic gates
I added a two-layer loop:
- AI does scoped implementation and refactoring
- Human controls intent and the invariant boundaries
- each stage must pass deterministic checks before next step
This changed the failure mode from “looks done” to “proves behavior.”
The workflow moved from “driver binds” to “system behavior,” such as:
- filesystem integrity through format/mount/write/readback
- integrity checks with deterministic roundtrips
- interrupt and BAR behavior verification under pressure
In this phase, AI became a fast executor of clearly bounded work. Human judgment became the gatekeeper for semantic correctness.
Stage III: bug-driven hardening
When systems pass in most cases, remaining bugs are adversarial:
- sustained I/O pressure
- queue lifecycle transitions
- reconnect and retry sequences
I adopted a strict rule:
- every fix must be minimal
- every fix must be log-backed
- no gate weakening
At that point, the work is less creative and more architectural.
The objective moved from adding features to making failure visible and then impossible to ignore.
What “works” means now
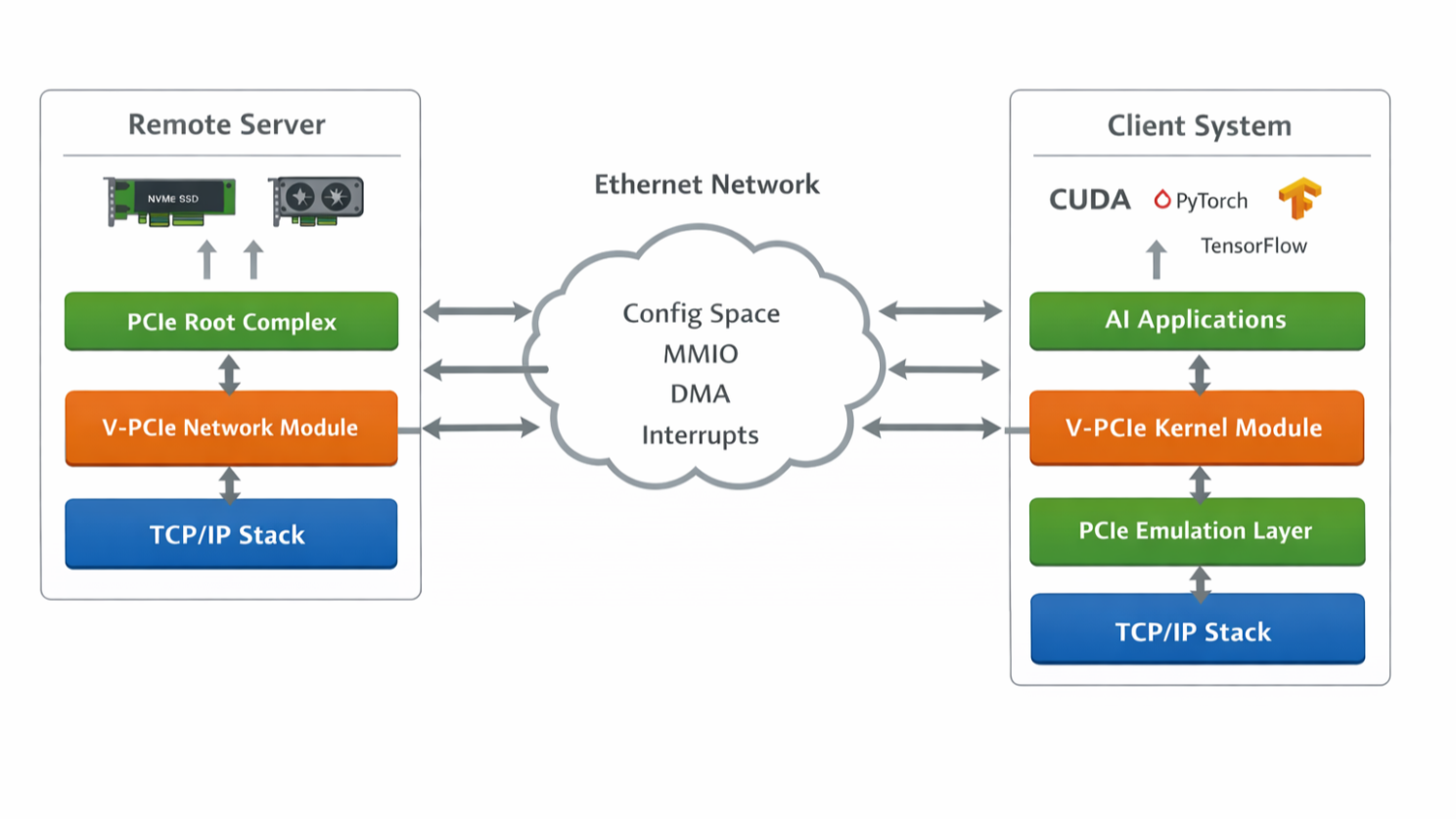
The result is a PCIe-over-network attachment model where Linux can attach remote PCI functions as if local, without forcing drivers and applications to rewrite for the transport.
In practical terms:
- native Linux devices can bind through the remote attachment path
- task lifecycle and resource mapping become explicit
- failure surfaces are narrowed into a smaller, more testable contract
This is not a “product” announcement. It is an architectural feasibility claim:
- if device attachment contract is stable, software stacks can scale without matching architectural rewrites.
What this experiment means
- It is a compatibility argument
Scaling hardware no longer has to mean distributed software complexity at every layer. A stable attachment model can keep much of the software stack stable while increasing device scale.
- It maps the real boundary between AI and human
AI is fast at scaffolding and implementation.
Human-led engineering is required for:
- contract selection
- invariant definition
- deciding when a fast path is a trap
- It suggests where future elasticity can move
If devices can be attached into an extended PCI domain, infrastructure can evolve below the driver layer instead of forcing repeated application-level rewrites.
Reflection
AI in this project was never “the engineer.”
It was a very fast execution partner.
The true engineering load was:
- learning unfamiliar subsystems quickly
- distinguishing demo-appearance from system truth
- hardening behavior where logs and invariants disagree
- preventing shortcuts that preserve demos but break architecture
In no-man’s-land problems, that division of labor matters more than model quality alone.
Conclusion
Today’s AI collapses implementation cost, not conceptual difficulty.
If you combine AI speed with strict verification, clear scopes, and disciplined human constraints, it becomes a practical accelerator for deep systems work.
In my case, that was enough to move PCIe semantics from an architectural curiosity into a working systems direction.