The AI industry is entering a new phase of infrastructure scaling. For years, hyperscale networking mostly focused on increasing bandwidth: 100G, 200G, 400G, 800G, and now 1.6T and beyond.
But as GPU clusters scale toward hundreds of thousands, and eventually possibly millions, of accelerators, another problem becomes harder to ignore. The challenge is no longer only total bandwidth. The challenge is how to scale extremely high-speed transport domains themselves.
Modern AI workloads, especially distributed training and large-scale inference, generate enormous synchronized communication patterns. These patterns create pressure on switch ASIC cache, congestion coordination, retransmission domains, transport state tracking, fabric scheduling, and burst absorption.
At small scale, modern RDMA and Ethernet fabrics work extremely well. At extreme AI scale, the physics of one giant high-speed transport domain becomes increasingly difficult to scale efficiently. This is where MRC-like architectures become interesting.
The Hidden Problem
Many AI networking discussions focus on bandwidth numbers. In practice, the more difficult problem is transport pressure itself.
As SerDes speeds continue increasing, every microsecond of congestion creates much larger pressure inside the fabric. A 100G transport domain may be manageable. A 400G domain amplifies the same congestion into roughly 4x pressure. An 800G domain, and eventually a 1.6T domain, becomes much harder to coordinate.
This pressure appears as larger switch buffer requirements, larger congestion domains, harder retransmission coordination, larger cache pressure, larger synchronization storms, and harder thermal and power scaling inside ASICs.
At hyperscale, switch ASIC cache and transport coordination become fundamental scaling bottlenecks. Increasing switch buffer size is extremely difficult: high-speed SRAM is expensive, larger cache arrays consume significant power, thermal density rises quickly, die area scaling becomes inefficient, and routing complexity increases dramatically.
The problem is not only networking anymore. It is transport physics at scale.
One Bigger Pipe
Historically, networking evolved toward larger centralized systems: faster SerDes, larger switch ASICs, deeper shared buffers, higher radix switches, and larger Clos fabrics. This worked extremely well for traditional cloud workloads.
AI traffic is different. AI synchronization traffic is bursty, globally synchronized, massively parallel, latency-sensitive, and highly correlated. Collective operations such as all-reduce can create synchronized traffic storms across thousands of GPUs at the same time.
The network is no longer simply carrying independent application flows. It is coordinating distributed computation itself. That changes the scaling problem completely.
The MRC Direction
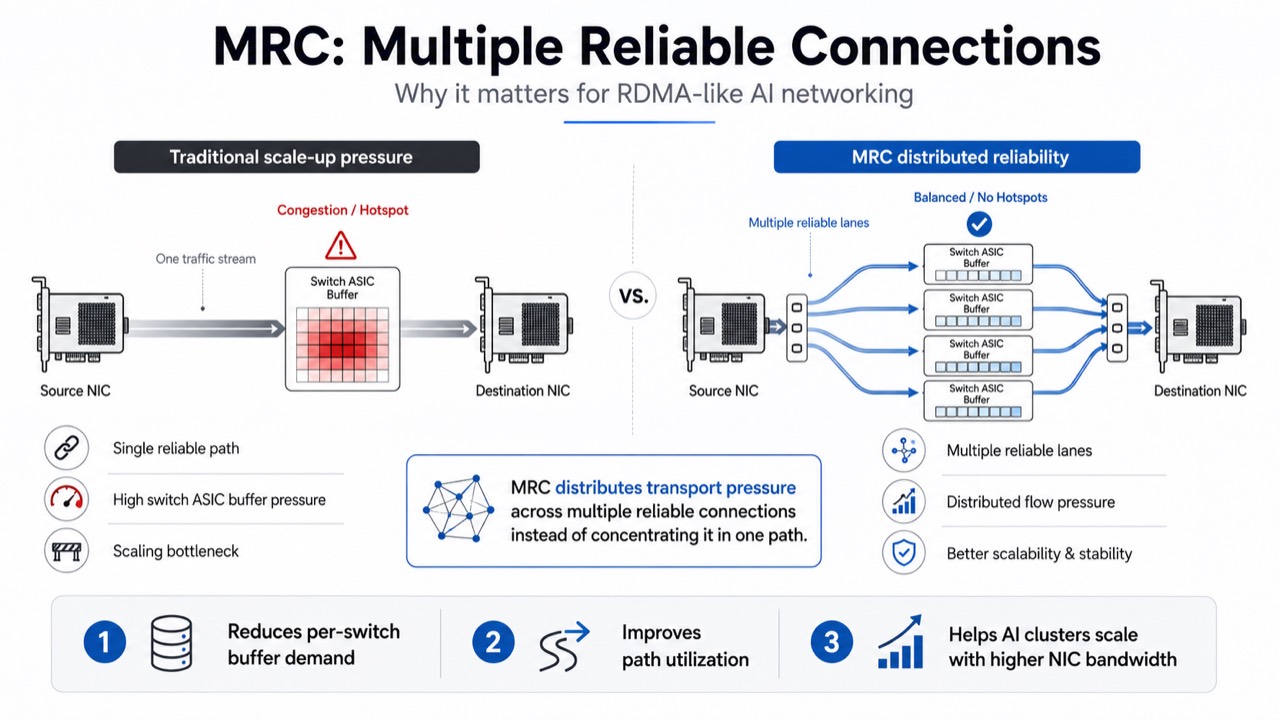
MRC-like architectures suggest another direction. Instead of building one increasingly massive transport domain around ultra-fast SerDes, communication can be split into many smaller transport lanes that operate together as one logical bandwidth fabric.
Conceptually, one 800G transport becomes multiple smaller transport lanes. One large congestion domain becomes many smaller domains. One massive buffering problem becomes distributed buffering. One monolithic transport pipeline becomes a set of parallel transport fabrics.
The key idea is not reliability by itself. The key idea is scalability of transport physics.
As SerDes speeds increase, scaling one giant transport domain becomes increasingly difficult: larger burst amplification, larger cache pressure, harder congestion coordination, larger retransmission domains, higher thermal and power density, and increasingly difficult ASIC scaling.
Splitting transport into many smaller lanes naturally reduces these pressures. Reliability improvements then emerge as a byproduct, because congestion, retransmission, and buffering become more distributed.
Why the Split Matters
Consider two simplified designs. At first glance, both provide the same total bandwidth:
Two simplified transport designs
| Design | Endpoint view | Fabric design | Pressure behavior |
|---|---|---|---|
| Case A: 1 x 800G | One 800G transport domain | One large 800G Clos fabric | Pressure concentrates into one giant domain |
| Case B: 8 x 100G | Eight smaller transport lanes | Eight smaller Clos fabrics or logical planes | Pressure distributes across many smaller domains |
In Case A, switch cache pressure concentrates into one domain. Congestion coordination becomes global. Retransmission domains become massive. Burst amplification becomes extremely large.
In Case B, each lane carries only 1/8 of the pressure. Congestion becomes more localized. Buffering becomes distributed. Transport coordination becomes parallelized.
This does not mean real systems automatically become 64x faster. Real performance still depends on workload communication patterns, congestion feedback, path quality, packet ordering, retransmission behavior, and topology design.
Architecturally, however, the direction matters. The network no longer scales by making one pipe infinitely bigger. It scales by distributing transport pressure across many smaller coordinated lanes.
The Fabric Joins the Transport
The more interesting implication is that splitting technologies should not only exist at the NIC layer. The deeper opportunity may exist inside the switch fabric itself.
Future AI fabrics may become path-aware, congestion-aware, topology-aware, pressure-aware, and scheduling-aware. At that point, the switch fabric is no longer simply forwarding packets. It is actively distributing transport pressure across the network.
This represents a major philosophical shift from traditional Ethernet thinking. Historically, networks optimized packet delivery. Future AI fabrics may optimize distributed compute coordination itself.
The network begins behaving less like a collection of routers and more like a distributed interconnect fabric.
Why It Starts Looking Like NVLink
This also explains why MRC-like architectures increasingly resemble NVLink-style fabrics.
Traditionally, NVLink and NVSwitch belonged to scale-up systems, while RDMA and Ethernet belonged to scale-out systems. That boundary is starting to blur.
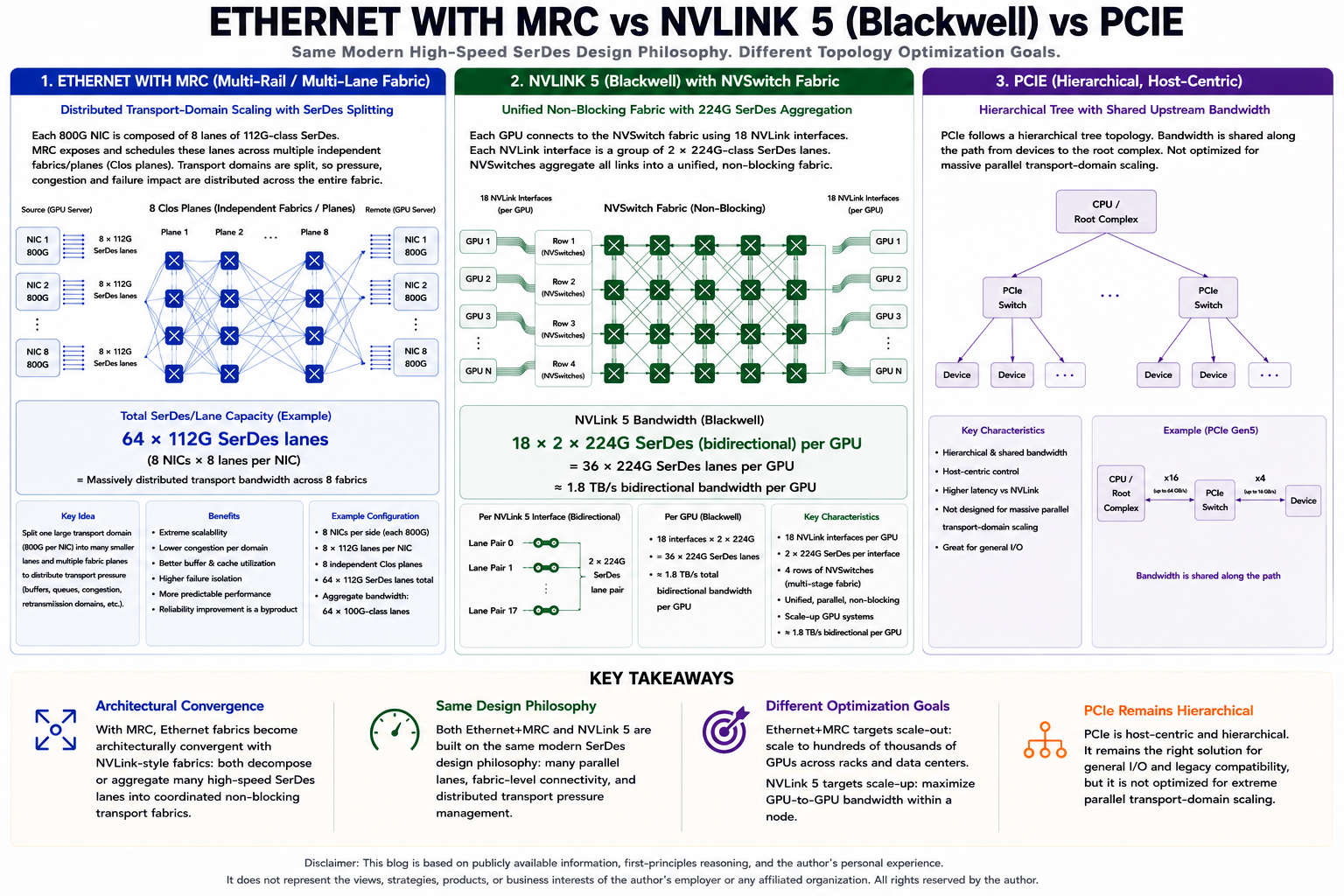
When NVIDIA states NVLink bandwidth such as 1.8 TB/s, that bandwidth is not coming from one gigantic monolithic connection. Internally, it is aggregated from many parallel high-speed SerDes lanes operating together as one coordinated fabric.
Conceptually, NVLink already follows a distributed-lane philosophy: many parallel SerDes, distributed transport lanes, aggregated logical bandwidth, topology-aware coordination, and fabric-level scheduling.
NVLink does not achieve extreme bandwidth through one infinitely fast pipe. It achieves it through many coordinated smaller pipes operating together. That starts looking remarkably similar to MRC-like thinking in Ethernet and RDMA fabrics.
As Ethernet SerDes speeds continue increasing, splitting communication into multiple distributed lanes begins to resemble NVLink-style communication more and more: aggregated logical bandwidth, distributed physical transport, parallel transport domains, topology-sensitive scheduling, and fabric-aware communication.
The architectural similarity becomes difficult to ignore.
The PCIe Topology Question
An important distinction still exists. Today, Ethernet and RDMA largely continue operating above traditional PCIe hierarchy models. The PCIe topology itself has not fundamentally changed yet. This may become another major hardware innovation frontier.
Currently, NVLink innovates heavily at the fabric layer, Ethernet innovates at the transport layer, and PCIe still largely follows classical root-complex and device hierarchy assumptions.
Future AI systems may challenge this separation. If networking continues moving toward distributed transport lanes, deterministic communication, topology-aware orchestration, memory-centric transport, distributed buffering, and GPU-direct communication, then the boundary between network fabric and system fabric may become increasingly unclear.
At that point, PCIe, NVLink, RDMA, Ethernet, and CXL may no longer be viewed as completely separate architectural worlds. They may be converging toward one larger direction: a unified distributed compute fabric.
Reflections and Takeaways
For decades, networking innovation focused on flow control: congestion management, routing algorithms, retransmission logic, queue optimization, fairness scheduling, and transport coordination. Many brilliant engineers spent decades making packet networks increasingly intelligent.
At extreme AI scale, another possibility emerges. The network may be simplifying into something closer to a giant distributed crossbar: less packet-by-packet decision making, more predictable, parallel, low-latency movement between massive compute domains.
This also changes how we think about networking itself. The network stops being only a communication system. It starts becoming the system bus of a distributed computer.
Perhaps this is the deeper meaning behind MRC-like architectures. Not merely improving reliability, but fundamentally changing how ultra-fast transport domains scale in future AI systems.
“Nevertheless, the scaling problem eventually becomes a networking problem again, just as NVIDIA recognized at the very beginning with NVLink fabrics. In the end, networking arrives both first and last — first in a different form, and eventually in the same form again.”