This article is not a defense of Huawei's Tau theory. I do not think Tau Computing should be treated as a completely new physical law. But I also do not think it should be dismissed as pure marketing. The interesting question is why Huawei chose this language now, and what kind of architectural pressure forced this idea to appear.
TL;DR
- Tau is a powerful but imperfect name. The more precise concept is Delta Tau: the time interval between useful computational events.
- Huawei's public language mixes two ideas: Tau as the target metric, and LogicFolding as one possible physical mechanism.
- The folding-city metaphor helps explain the intuition: not only more skybridges between chip islands, but folding the city so distant units become adjacent.
- From a first-principles AI infrastructure view, Tau Computing may be about whether GPU-cluster networking problems can be folded back into IC design.
- The idea is interesting, but still incomplete. The hard questions are the basic unit, link orchestration, timing closure, heat, yield, and software mapping.
Part 1: Why Tau? Is Tau a good name?
Before we talk about Tau Computing, we need to ask a more basic question: why is it called Tau?
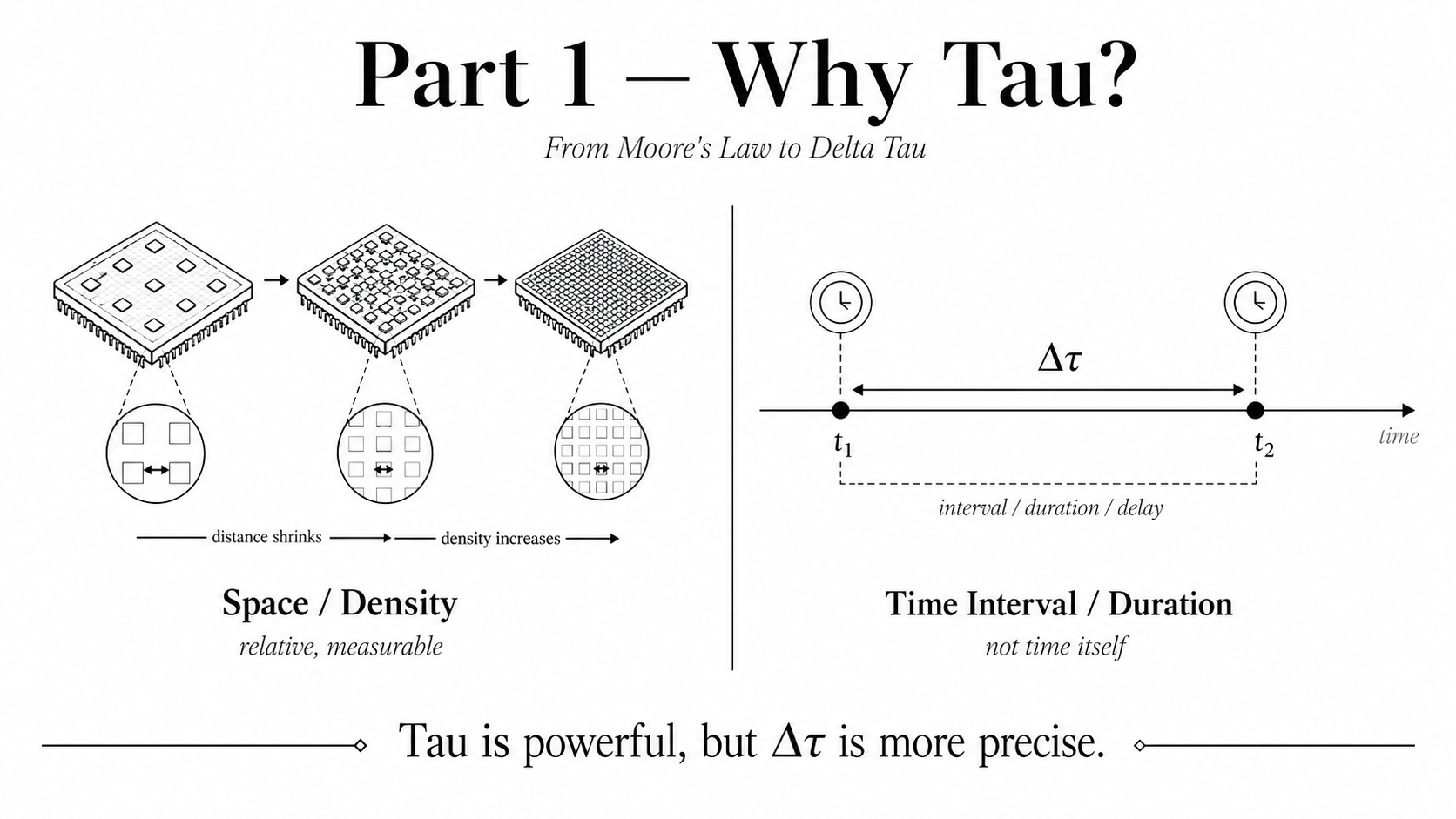
Moore's Law is easy to understand because it is fundamentally a law of space. More precisely, it is a law of density. In the semiconductor industry, we measure progress by how many transistors can be placed into a given area, or how much distance can be reduced between physical structures. This is why process nodes, transistor density, feature size, and chip area became natural languages for computing progress.
This measurement is not perfect, but it is meaningful. Distance is a relative measurement. Density is also a relative measurement. When we say a semiconductor process improves from one generation to the next, we are comparing one physical geometry against another. The transistor becomes smaller. The distance becomes shorter. The density becomes higher. Moore's Law gives us a relative and measurable way to describe semiconductor evolution in the spatial domain.
But Tau is different.
Tau, as a Greek letter, is commonly used to represent time or a time constant in physics, circuits, and systems. At first glance, this sounds elegant. If Moore's Law describes space scaling, then Tau Scaling may describe time scaling. If the old computing law is about shrinking distance, the new computing law may be about shrinking time.
But here we need to be careful. Time itself is not the correct counterpart of distance.
In physics and engineering, when we compare movement, propagation, delay, or evolution, we do not usually measure time as an absolute concept. We measure duration. We measure interval. We measure delay. We measure Delta Tau.
In spacetime thinking, the counterpart of distance is not simply time. It is time interval. Just as we care about Delta x in space, we should care about Delta Tau in time.
This distinction matters. You cannot really say we compress time in an absolute sense. Time is not a piece of material that can be folded like silicon area. Time is not directly scalable like transistor density. What we can reduce is duration. We can reduce propagation delay. We can reduce access latency. We can reduce synchronization time. We can reduce the interval between request and response, between memory and compute, between chip and chip, between one part of the system and another.
So if Huawei's ambition is to find an alternative representation of distance in the time domain, then Tau is understandable, but not fully precise. A more accurate concept would be Delta Tau Computing.
The naming is therefore both powerful and imperfect. It is powerful because it points to the right historical transition: from space-domain scaling to time-domain scaling. But it is imperfect because Tau alone sounds like we are scaling time itself. Strictly speaking, we are not scaling time. We are scaling latency, duration, and the time interval of computation.
The ambition is clear, even if the name is not mathematically perfect.
Part 2: What is Tau Computing from Huawei's idea?
If Tau is not perfectly precise as a name, the next question is: what does Huawei actually mean by it?
From Huawei's public description, Tau Computing, or Tau Scaling Law, is presented as a new path beyond traditional Moore's Law. Huawei's public framing emphasizes reducing signal propagation delay, using LogicFolding to shorten internal wiring paths, and extending the approach across circuits, chips, and larger computing systems. Reuters summarized Huawei's announcement as focusing on cutting the time it takes signals and data to move through chips and computing systems, rather than relying only on shrinking transistors. Other reports describe LogicFolding as a move from traditional 2D layouts toward layered 3D structures that shorten wiring and reduce resistance-capacitance delay.
But if we read the idea more aggressively, the deeper question is not only layered 3D. It is whether the topology of logic itself can be folded, so that physical adjacency and temporal adjacency are redesigned together.
But to understand Huawei's idea clearly, we need to point out two ambiguities.
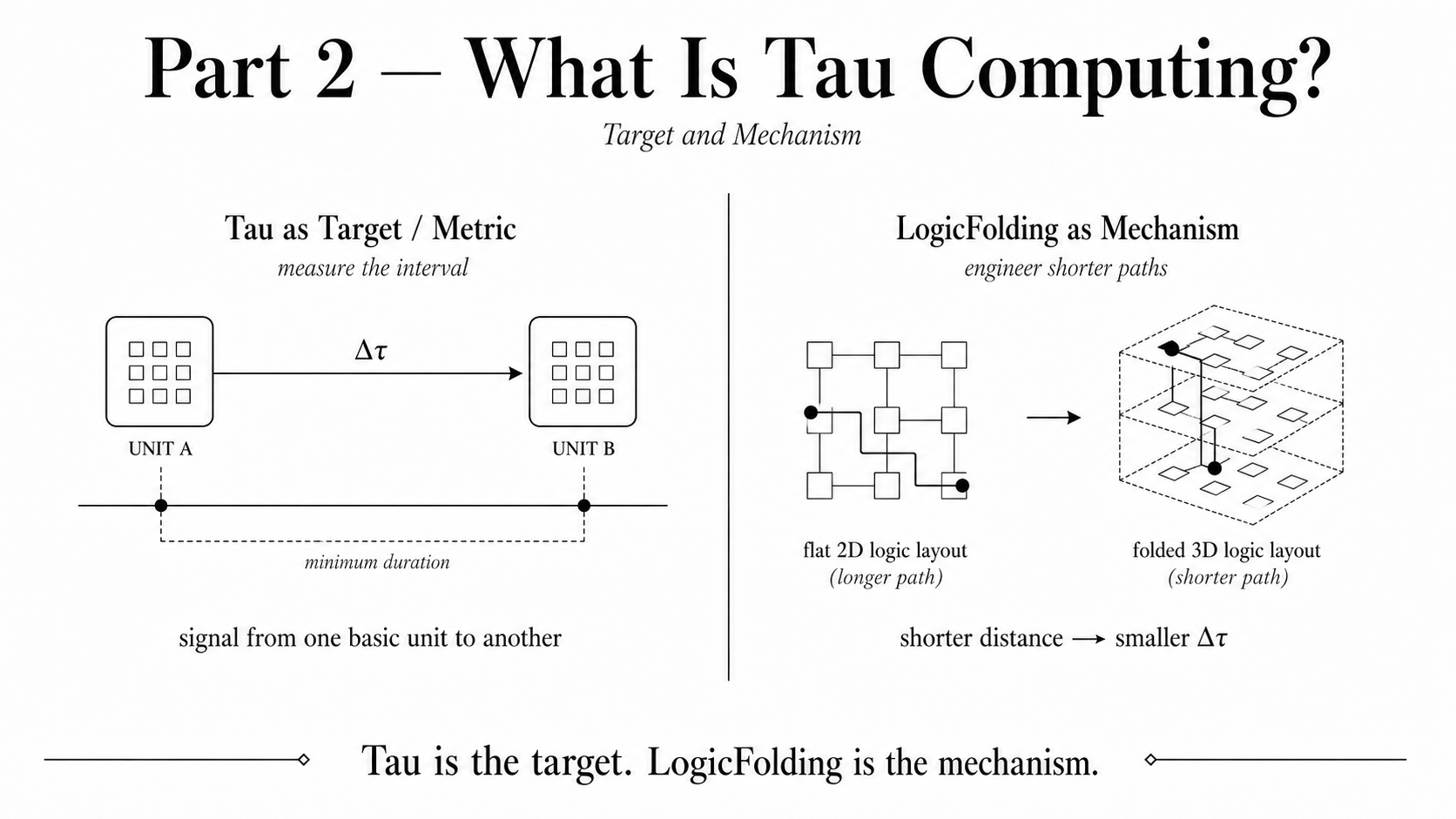
The first ambiguity is the meaning of Tau. Huawei refers to Tau as a time constant, but in computing architecture, the useful concept is not abstract time itself. The useful concept is the minimum duration for a signal to move from one basic unit to another basic unit.
That basic unit can be a transistor, a logic gate, a memory block, a chiplet, an accelerator, or even a node inside a supernode. So Tau should not be understood as time in an absolute sense. It should be understood as Delta Tau, the time interval required for useful information to propagate from one computational unit to the next.
The second ambiguity is the meaning of LogicFolding.
LogicFolding may sound like a new density technique, but its deeper meaning is to reduce time by reducing space. Traditional chip design is mostly 2D, or 2.5D through packaging and interposer-style integration. LogicFolding tries to move toward a more compact 3D, or truly 3D, organization of logic. The goal is not only to place more logic in the same area, but to shorten the distance between basic units.
Shorter distance means smaller wire delay, lower parasitic effect, lower RC delay, and therefore smaller Delta Tau.
This is the real conceptual shift. Huawei is still using spatial engineering, but the optimization target changes. The goal is no longer only transistor density. The goal is the minimum useful time interval between computational units.
Once Tau is understood as a possible measure of Delta Tau between computing units, LogicFolding becomes more than a density technique. It becomes a spatial method to change temporal distance. This leads to the deeper question: why does this time-domain language matter now?
Part 3: Why time-domain scaling matters now
Why does Huawei use time scaling to describe its design philosophy?
At first glance, it may sound like a marketing phrase. If the real engineering direction is 3D IC and LogicFolding, why not simply say that? Why introduce Tau, a symbol of time?
The deeper answer may be this: Huawei is not only proposing a new packaging method. It is proposing a new way to imagine the geometry of computation.
Traditional Moore's Law is largely a law of space on a 2D surface. We shrink transistors, reduce feature size, and place more logic on a flat plane. In that world, chip design is like building a city on flat land. Different functional blocks are different buildings. Wires are roads. The main challenge is how to place those buildings better and how to route the roads more efficiently across the surface.
This worked extremely well for decades. But it also created a mindset.
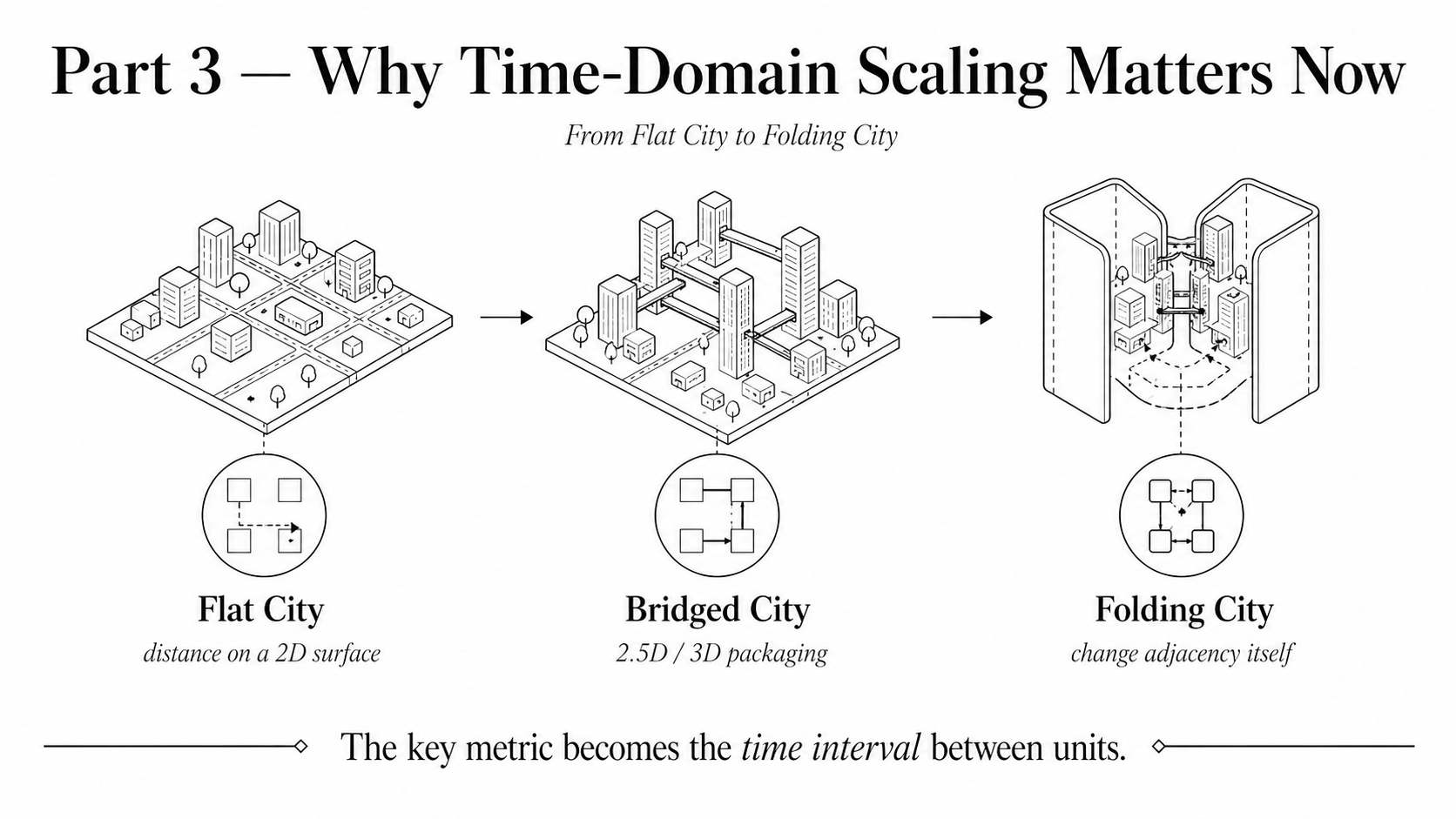
We became very good at designing chips like flat cities. We became very good at thinking about distance as surface distance. We became very good at optimizing area, layout, routing, and density inside a two-dimensional world. Even when the industry moved toward 2.5D and 3D packaging, much of the thinking still stayed close to this city model.
In this metaphor, 2.5D and many forms of 3D packaging are like building skybridges between buildings. Chiplets, interposers, HBM stacks, and advanced packaging are all important steps. They put different buildings closer together. They create wider roads. They build faster bridges. They reduce some travel distance between islands.
But in many cases, the basic structure is still the same: there are separate buildings, and we connect them through selected bridge points.
Huawei's LogicFolding seems to suggest something more radical. Instead of building a city on a flat surface and then connecting the buildings with better roads and skybridges, Huawei wants to fold the city itself.
This is a very different concept. A folding city is no longer just a flat map with a few vertical add-ons. When the city is folded, locations that were far apart on the flat surface can become close to each other in the folded structure. Streets that used to require long travel may now meet through internal adjacency. Different layers are no longer separate islands waiting for bridges. They become parts of one connected volume.
In chip language, this means the goal is not merely to connect separate logic blocks better. The goal is to reorganize the logic itself into a folded three-dimensional structure, so that the basic computational units are naturally closer to one another.
That is why the language of time begins to matter.
If Moore's Law measures progress by spatial density, then a folded city suggests another metric: not only how much logic fits in a given area, but how quickly one part of the structure can affect another. Once the city is folded, the key improvement is not only in geometry. It is in the minimum duration of signal movement between units.
Strictly speaking, the better term would be Delta Tau. The issue is not time in the abstract, but the time interval needed for a signal to travel from one basic unit to another. But the reason Huawei uses Tau becomes clearer here. When you fold the city, what changes most is not only shape. What changes most is the effective temporal distance inside the structure.
And once adjacency changes, signal delay changes.
This also explains why the idea appears now. The old 2D city is reaching its limits. Spatial shrink on a flat surface has become harder and more expensive. At very small dimensions, device behavior becomes harder to control. Leakage, variability, tunneling, noise, and other physical effects make classical signal design more difficult. Ironically, while people are excited about quantum computing, in classical chip design the quantum effect is often not a friend. It can destroy the clean signal boundary that classical computing depends on.
A classical chip needs stable states. It needs predictable signal paths. It needs controllable isolation between units. But as physical dimensions shrink further, the system becomes harder to isolate and harder to predict. So the industry cannot only keep asking: how do we make the 2D city smaller?
It must ask a new question: can we change the shape of the city?
This is why LogicFolding is interesting. It tries to use a higher-dimensional spatial structure to reduce the time interval between units. It does not simply add a bridge between two faraway buildings. It changes the map so that those buildings are no longer far away in the first place.
So did Huawei really explain how to do this? This is where the idea becomes interesting, but also ambiguous.
From the naming of Tau and the concept of LogicFolding, we can see two different ideas mixed together. Tau points to the time-domain target: reduce the effective duration between computational units. LogicFolding points to the spatial method: fold the physical layout so that distant units become closer.
One is the metric. One is the mechanism. But in Huawei's public explanation, these two concepts are not fully separated. Sometimes Tau sounds like a new law of time. Sometimes LogicFolding sounds like a new form of 3D IC density scaling. Sometimes the whole idea sounds like semiconductor physics, and sometimes it sounds like system architecture.
This ambiguity is not necessarily a weakness. It may simply show that the idea is still in an early stage. Huawei seems to know that the old 2D city cannot scale forever. It seems to know that only building more roads, wider roads, or skybridges between chip islands is not enough. It also seems to know that the next step must change the topology of computation itself.
But the public language has not yet fully explained the deeper mechanism. What exactly is the basic unit being folded? How is logic placed in this higher-dimensional structure? How is signal integrity maintained? How are power, heat, yield, routing, timing closure, and software mapping handled? How does Delta Tau become a measurable design metric rather than a philosophical metaphor?
These are the real questions behind Tau Computing. This leads to the next part: what Huawei did not fully say.
Part 4: What Huawei did not fully say
What is Tau Computing really trying to solve?
If we only read it as a semiconductor slogan, it sounds abstract. Time scaling, LogicFolding, Delta Tau, higher-dimensional design: these are interesting words, but they are still far away from real engineering pain. So let us start from a real problem.
The real problem today is GPU computing scaling.
Modern AI computing is no longer about one GPU. A large model does not live comfortably inside one chip. Training does not run efficiently on one accelerator. Even inference is becoming a multi-GPU, multi-memory, multi-node system problem. The real machine is now a group of GPUs, HBM, CPUs, NICs, switches, and memory systems working together.
So the question becomes: how do we efficiently scale computing across multiple GPUs and multiple memories?
Today, the industry mainly answers this question through two directions: scale-up and scale-out.
Scale-up tries to make GPUs inside one server, one tray, one rack, or one supernode behave like a closer computing body. NVIDIA NVLink and NVSwitch are the best-known examples. Scale-out tries to connect many nodes into a larger cluster through RDMA, InfiniBand, Ethernet, Clos networks, and multi-plane fabrics.
Both directions are trying to solve the same fundamental problem: GPU-to-GPU communication.
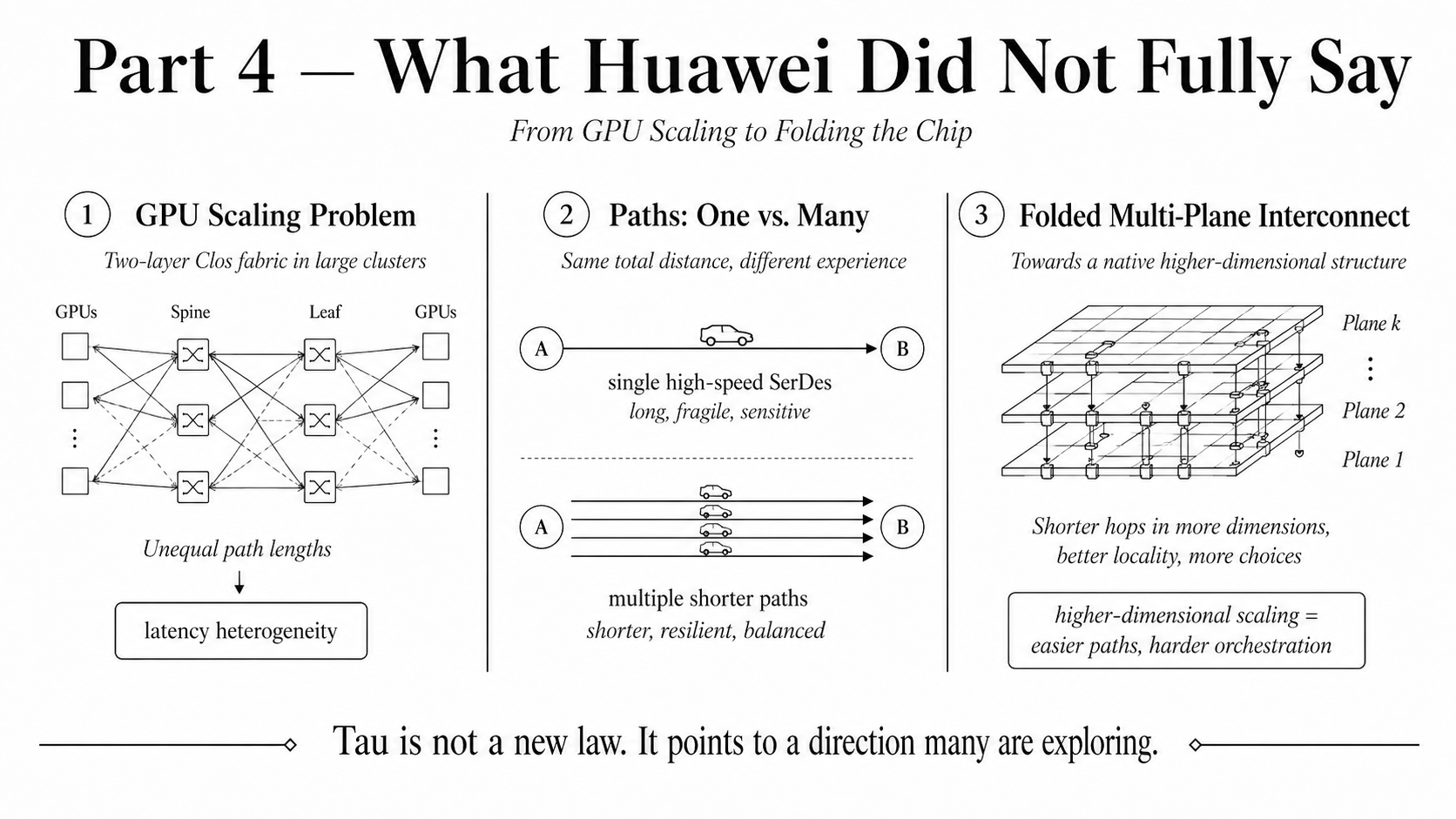
But once the system becomes large enough, topology becomes the real bottleneck. In a simple one-switch system, the communication path is relatively uniform. Each GPU can reach another GPU through a similar structure. The point-to-point latency between GPUs is more homogeneous.
But when the system grows, one switch is no longer enough. We move into two-layer Clos, then larger multi-layer Clos, and eventually multiple network planes. At that moment, GPU-to-GPU latency becomes less uniform. Some paths are closer. Some paths are farther. Some traffic crosses more hierarchy. Some communication waits behind more congestion, arbitration, or routing complexity.
This looks normal because we are used to it. In daily network engineering, heterogeneous latency looks like the natural price of scale. But from first principles, we can ask a different question: is heterogeneous GPU-to-GPU latency really a law of nature? Or is it partly a consequence of the topology we chose?
This is where Tau Computing becomes interesting.
To understand this more deeply, we can look at scale-up networking. NVLink is not a single magical wire. It uses many smaller high-speed links. These links connect through NVSwitch to form a scale-up fabric. From the city metaphor, NVLink and NVSwitch are like building many high-speed skybridges between GPU buildings.
This is powerful. The skybridges are fast, wide, and carefully designed. They make GPUs closer than traditional PCIe or scale-out networking. But fundamentally, it is still a bridge-based topology. We still have GPU buildings, and we use many high-speed bridges and switches to connect them.
So a natural question appears. If the goal is to make GPU-to-GPU communication more homogeneous and reduce the Delta Tau between GPUs, why only build more skybridges?
Why not fold the GPU city itself?
This is not necessarily what Huawei explicitly said. But from a system architect's point of view, this may be one possible way to read LogicFolding.
Instead of placing multiple GPU dies on a 2D substrate and connecting them through 2.5D packaging, interposers, or external fabrics, perhaps we can imagine a more hierarchical and truly three-dimensional layout. GPU compute units, memory units, and communication units may be placed in a folded structure, so that the basic paths are shorter and more homogeneous from the beginning.
In this interpretation, LogicFolding is not only about making one chip denser. It is about asking whether the communication topology between computing units can be redesigned before it becomes a large external network problem.
In other words, instead of solving latency heterogeneity after the system expands into a Clos network, can we reduce the source of that heterogeneity at the physical layout level?
This is a powerful idea. But is it completely new? Maybe not.
In recent AI networking, we already see a similar direction through MRC and multi-plane network designs. The purpose of multi-plane networking is not only to increase bandwidth. It is also to change the topology.
Here we need to be precise. Multi-plane networking does not simply reduce dimension. More accurately, it represents a higher-dimensional communication structure through multiple lower-dimensional slices. A hierarchical Clos scales by adding more layers in one structure. A multi-plane fabric scales by creating several independent communication planes. Each plane may remain relatively shallow, but together they form a richer, higher-dimensional communication space.
This is why multi-plane design can increase scalability while reducing effective network depth and latency heterogeneity.
So from this perspective, the industry has already discovered an important principle at the network level: when one plane cannot scale, create multiple planes. When one flat communication surface becomes congested or too hierarchical, represent the higher-dimensional communication problem through multiple independent slices.
This is where Huawei's Tau Computing may become more interesting.
Perhaps Huawei is trying to apply this same idea back into IC design. Can we make the chip itself multi-plane natively? Can we turn the GPU die, memory die, interconnect fabric, and logic blocks into a folded internal topology, instead of building a mostly 2D structure and then using external bridges to repair the distance problem?
Again, this is my interpretation from first principles, not a confirmed implementation detail from Huawei. But it may explain why Tau and LogicFolding appear together.
Tau gives the time-domain target: reduce Delta Tau. LogicFolding gives a possible spatial mechanism: fold the structure so that communication units become closer in effective topology.
The direction is attractive. In theory, a higher-dimensional or multi-plane structure can help latency and scalability. If the same number of computing units can be connected through a more direct, more homogeneous, and more multi-plane structure, then Delta Tau should decrease. Less waiting. Less path heterogeneity. Less synchronization penalty. Better parallel efficiency.
But this also introduces very hard problems.
Both NVLink and multi-plane networks rely on multiple links from the basic unit. A GPU has many NVLink connections. A node may connect to multiple network planes. The architecture works because the basic unit is large enough to expose, manage, and orchestrate many links.
If we bring this idea into IC design, the questions become much sharper.
First, what is the basic unit in the IC world? Is it a transistor? A gate? A standard cell? A logic block? A memory-compute tile? A GPU slice? A chiplet? A compute-memory island? The answer matters because the smaller the unit becomes, the harder it is to give that unit multiple meaningful links.
Second, how do we orchestrate multiple links inside such a small unit? At the network level, we can use routing, scheduling, load balancing, congestion control, and software policies. At the IC level, everything becomes more constrained. Timing closure becomes brutal. Wire delay, clock distribution, skew, power delivery, thermal density, signal integrity, and manufacturing yield all become part of the same problem.
This is the real difficulty behind Tau Computing. It is easy to say that we should fold the city. It is much harder to define what the city block is, how many internal roads it has, how traffic is scheduled, and how the whole folded city still runs with predictable timing.
So can Tau Computing change the landscape of IC design or GPU cluster computing? In theory, perhaps yes.
If Huawei can turn LogicFolding into a real native multi-plane IC design, it may reduce some external topology complexity. It may make GPU-to-GPU or compute-to-memory communication more homogeneous. It may reduce the effective Delta Tau between units. It may shift part of the networking problem from the system level back into chip architecture.
But the key word is if.
The public explanation has not yet answered the most important engineering questions:
- What is the basic unit?
- How many links does each unit have?
- How are those links physically implemented?
- How is timing closure achieved?
- How is heat removed from a folded structure?
- How does software understand and exploit this topology?
- How does this approach compare with NVLink, multi-plane RDMA, MRC, CXL, and advanced packaging?
This is why Huawei's Tau Computing is both exciting and incomplete. It seems to see the right problem: GPU computing is becoming a topology problem. It seems to suggest the right direction: reduce Delta Tau by changing the physical and logical topology. But it has not yet fully explained the real mechanism: how to build, control, and program a native multi-plane IC fabric.
One possible deeper interpretation is this: Huawei may be trying to change the design philosophy from pushing one extremely high-frequency SerDes path harder and harder, toward building multiple shorter, folded, 3D-stacked SerDes-like paths.
Traditional scaling often tries to make one road faster: higher frequency, higher signaling rate, tougher equalization, harder signal integrity, more power, and more analog complexity.
Tau-style scaling may ask a different question. Instead of making one long road faster, can we fold the structure and create many shorter roads?
If this interpretation is right, then LogicFolding is not only a 3D IC idea. It is a multi-plane communication idea inside the chip. The goal is to reduce Delta Tau not only by increasing frequency, but by changing topology so each path becomes shorter, more local, and more homogeneous.
That may be the most important thing Huawei did not fully say.
Final reflection: high-dimensional scaling
In the end, this article is really about how we scale.
One way to scale is to make a single road faster. In interconnect language, this means pushing a single SerDes path from 112G to 224G and beyond. This path usually requires more advanced signaling, better analog design, stronger equalization, higher power budget, and often more advanced process or packaging support.
Another way is to split the road. Instead of one 224G-class path, we may use multiple lower-speed paths, such as four 64G-class SerDes paths. Each path may be easier to build and may not require the same level of advanced process or analog difficulty. But the complexity does not disappear. It moves into orchestration.
Once we create multiple paths, the endpoint is no longer a simple one-road problem. It becomes a higher-dimensional problem. The endpoint must decide how traffic enters these paths, how flows are balanced, how ordering is preserved, how congestion is controlled, how failures are handled, and how the multiple planes still behave like one useful communication fabric.
Metaphorically, it is almost like entering a multiverse. In a 2D world, there is one road or one surface. In a higher-dimensional world, there are multiple planes, multiple paths, and multiple possible routes. Many scaling issues that are painful in a flat 2D topology may become easier in a higher-dimensional structure. But the price is that we must learn how to enter, coordinate, and orchestrate these multiple worlds.
Science fiction often imagines space travel in a similar way. If we travel only through ordinary three-dimensional space, the distance between stars feels almost impossible. But if a higher-dimensional hop is possible, the same journey may become much shorter. That image may be one reason why the phrase LogicFolding is attractive: it suggests that instead of traveling farther and faster on the same surface, we fold the space so that distant points become closer.
This is why Tau Computing is not a new concept in a strict technical sense. The ingredients already exist in SerDes design, multi-lane links, NVLink, multi-plane networking, MRC, 3D packaging, and topology optimization. But Huawei's Tau language does point toward a real direction that many parts of the industry are already working on today.
Due to the scaling pressure of AI computing, we are entering an era of high-dimensional scaling. In this era, performance is not only about making one path faster. It is about creating more dimensions of adjacency, and then orchestrating them correctly.
That may be the real value of the Tau discussion. Not a new law, but a reminder that the future of computing scale may depend less on one increasingly impossible road, and more on many shorter roads that must be coordinated as one system.
References
- Reuters: Huawei proposes new path for chip development amid U.S. sanctions
- TechRadar: Huawei unveils new chip architecture and Tau Scaling Law
- Tom's Hardware: Huawei claims LogicFolding and Tau Scaling breakthrough
- Tom's Hardware: Peking University prototype EDA tool for LogicFolding
- Wired: Huawei's chip design strategy and Tau Scaling
- Open Compute Project: Multipath Reliable Connection specification
- OpenAI: Supercomputer networking to accelerate large-scale AI training